什么是Spark?
spark是一个分布式的内存计算引擎。由于在现在的环境下,单台计算机没有足够的计算资源进行大规模数据的计算,使得应用者能够在相对短的时间内获得计算的结果。spark的出现使得大规模数据计算可以在一群计算机之间展开,从而解决单台计算机计算资源不足的问题。spark是一个计算引擎,因此它主要关注的是如何在分布式的数据集上进行计算,而不关注数据如何进行分布式的存储。数据的分布式存储是HDFS这样的分布式存储系统管理的。
Spark应用程序的构成
Spark应用程序由一个driver进程(驱动程序)和一组executor进程组成。驱动程序负责运行main函数;维护spark应用程序的信息;响应用户的输入;分析、分配和调度executor的工作。executor实际执行驱动程序分配给他们的代码并将执行器executor的计算状态报告给驱动节点。driver和executor都运行于集群中的某个节点中,由资源管理器进行节点分配。
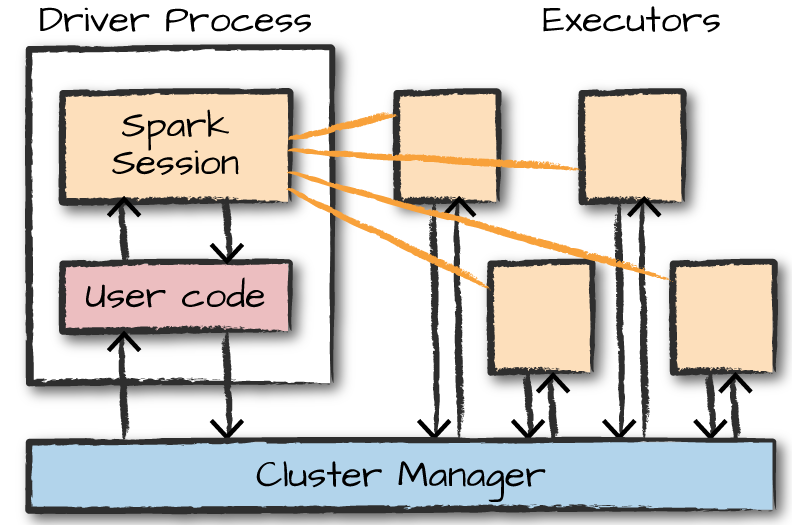
Spark中两种类型的操作
spark的操作可以大致分为两种类型,一种是转换操作(transformation),另一种是行动操作(action)。转换操作构建数据的转换逻辑,即将数据从一种状态、格式转换为另一种状态、格式。行动操作则触发实际的计算,通过结合一系列的转换操作得到最终行动操作的结果。
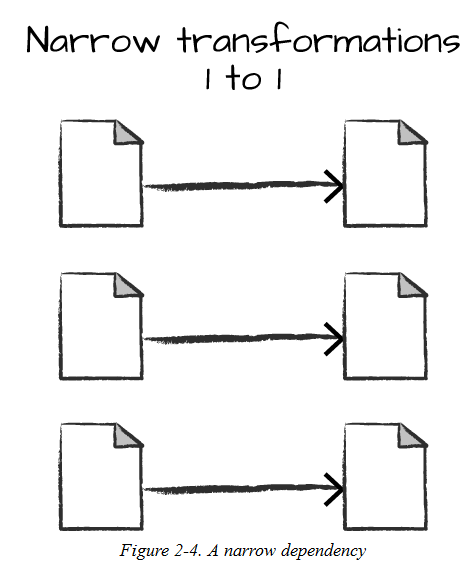
转换操作进一步可以概括为两种类型。一种是窄依赖,另一种是宽依赖。窄依赖操作的每个输入数据分区只对应一个数据输出分区,如下图:
宽依赖操作的一个输入数据分区对应多个输出数据分区,即一个分区需要从多个分区收集数据。下图右侧为输入数据分区,左侧为输出数据分区。
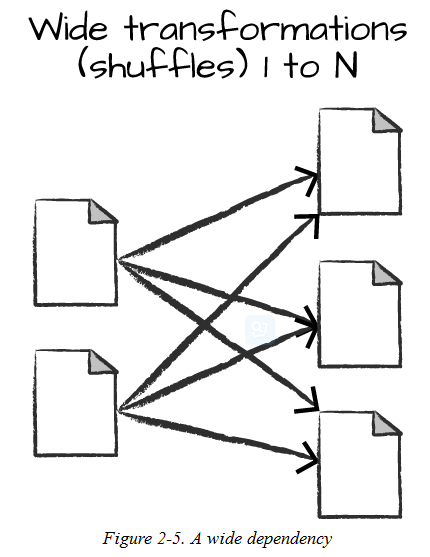
窄依赖因为只是一个分区到另一个分区的操作,因此可以在单独的分区进行计算,它不需要与其他分区的数据产生联系,并行度高。而宽依赖的输入分区需要结合多个输出分区,计算过程中可能产生分区之间的通信和shuffle操作,并行度将会受到影响。
延迟计算
spark不会在遇到转换操作后立即计算,得到转换操作的结果,而是在实际需要计算得到结果时(例如遇到行动操作),才会将之前设计的各种转换操作转换为一个物理计划,并在集群中尽可能高效的运行。这种方法可以端到端的优化整个数据流。而如果是采用即时计算的策略,那么用户的每个操作都要在集群中开始计算,优化操作只能计算当前的数据状态,后面的操作计划就无法考虑到。
其他
Spark UI是一个可视化界面,可以监控作业的进度。如何在单机和集群环境下启动和查看spark UI?
DataFrame是spark提供的一个结构换数据结构和API。类似pandas中的dataframe。
分区的概念。分区的概念目前还不是很清楚。
参考资料
《Spark - The Definitive Guide - Big data processing made simple》
spark权威指南翻译:https://zhuanlan.zhihu.com/p/82435914?utm_source=wechat_session