搜索引擎一直以来都是学习、查找资料的工具,是从海量网页查找有效信息的途径。搜索引擎的交互界面非常简单,通常只有一个搜索框,但背后涉及的技术却不简单。虽然一直都在使用搜索引擎,但是却从来没有仔细了解过背后的原理,对搜索引擎也没有整体的认识。由于即将从事搜索引擎相关的工作,遂通过这本书来扫盲。
2020年疫情期间在家花了大约一个星期的时间粗略阅读了这本书。首先个人认为这本书覆盖面比较广,涵盖了搜索引擎方方面面的内容,我也从这本书中建立起了对搜索引擎的一个整体认识。然而涉及的知识点较多,对于其中的算法细节我并没有花很多时间研究,等到具体需要攻克某方面的难点时再进一步查找资料学习。
对搜索引擎的整体认识
搜索引擎主要是为了完成一个任务,即根据用户的查询给用户返回相关的信息。然而这样一个看似简单的任务背后却涉及到了一系列的问题。
(1)首先是信息的获取。既然是要查询相关信息,那么首先需要有信息。对于通用搜索引擎而言,例如百度,谷歌等,需要处理的信息通常是互联网网页。对于垂直搜索领域而言,信息则是各种各样特定主题的数据,比如淘宝的商品数据、视频网站的视频数据。互联网网页的获取通过网络爬虫自动抓取。网络爬虫像蜘蛛网上的蜘蛛,在网上不停爬取网页,这就是书中第2章的内容——网络爬虫。在进行网络页面爬取的过程中,难免会存在网页内容近似甚至是重复的情况,即使已经根据url进行去重,但是不同网站的内容也可能会重复,这就是第10章的内容——网页去重。网页去重通过Shingling算法、I-Match算法、SimHash算法等算法根据网页的文字内容对网页进行去重。
(2)在获得数据后,就需要考虑使用什么数据结构来索引大量的网页,以便于快速针对用户查询返回相关内容。第3章内容介绍了倒排索引的知识。倒排索引的逻辑结构可以认为是词到包含该词的文档列表的映射。当数据量达到很大规模时,索引数据也会不断增大,对索引进行压缩有助于减少存储成本。第4章介绍了索引压缩。
(3)前面两步完成后,相当于准备好了可以检索的数据,索引的建立可以加快查询的速度。在此基础上,可以根据词匹配找到一批相关的文档。用户在前端的搜索框中输入关键词、查询短语、句子等期望搜索引擎可以返回一个排序的文档列表。这里涉及几个问题:首先,由于用户输入的内容通常非常短,了解用户的检索意图对于返回高质量的排序结果非常重要,但用户通常不会主动告诉搜索引擎自己的意图,因此对于用户的输入搜索引擎需要进行意图识别(第9章 用户查询意图分析),意图识别结果搜索排序过程。其次,通过对query分词后可以从倒排索引中返回一批包含该词的文档列表,但是该文档列表是“无序”的。而前几页的搜索结果对于搜索质量而言至关重要,因此需要对查询到的文档进行按照一定的算法进行排序。搜索排序从两个角度对文档进行排序,其一是文档和用户查询的相关性,第5章检索模型与搜索排序就介绍了布尔模型、向量空间模型、概率检索模型等检索模型,用来做用户query相关性排序;其二则是网页内容的质量,网页内容质量高的应该排在前面,这里涉及到链接分析。书中第六章介绍了pagerank、HITS、SAlSA等算法,用于评估网页的质量。网站开发者为了提高自己网站的网页排名,会根据搜索引擎的网页质量评估方法进行作弊,获得不符合网页内容的排名。书中第8章介绍了一些常见的作弊方法和反作弊方法。
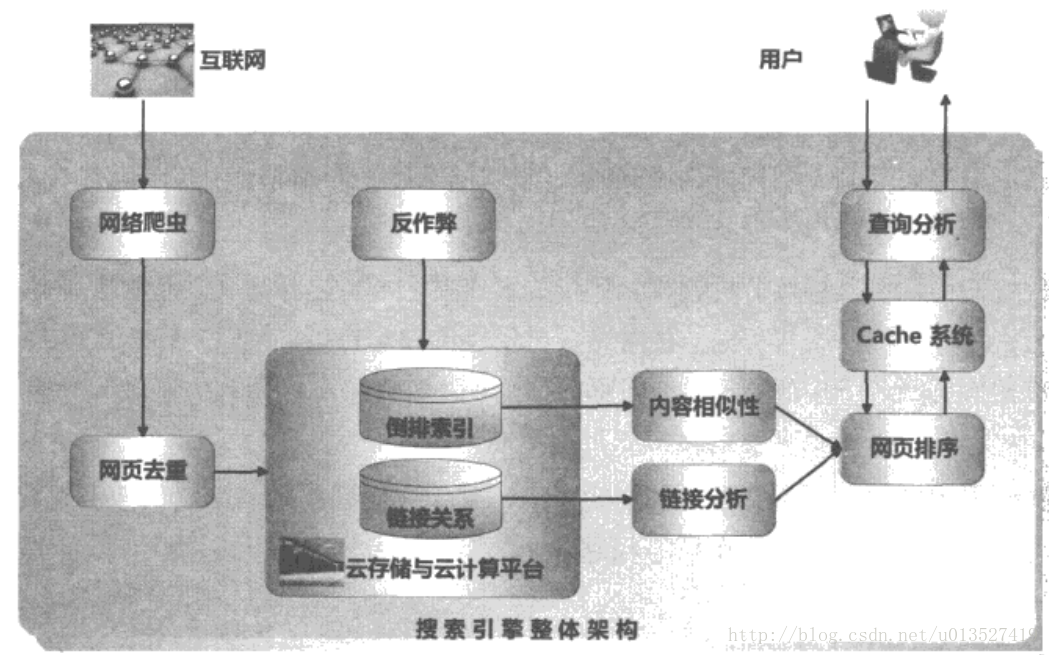
以上简述了搜索引擎从数据搜集到用户搜索的过程,同时给出了书中相关的章节。在阅读过程中没有仔细了解每个算法的具体细节,而是先建立起整体概念。
一些疑问
书中有很多未涉及的地方:(1)query重构和query纠错。query分析。(2)知识图谱等工作如何在搜索引擎中应用。(3)深度学习中的NER等技术是否有在搜索引擎中应用以及如何应用。(4)有相关博文介绍了谷歌应用BERT提升了搜索质量,这个是如何做到的。(5)
个人感兴趣的方向
一个是检索模型和搜索排序部分。在搜索过程中,用户通常对几条、前几页的内容感兴趣,如果前几页内容没有用户相关的内容,通常不会不断的往后翻页。检索模型正是用户解决结果排序的问题。检索模型包括布尔模型、向量空间模型、概率检索模型。基本思路都是通过向量化query和document,然后通过某种函数计算向量的距离表示相似度。一个好的向量表示对于最后相似结果的判断很重要。所以这是否是一个文本挖掘的问题。最近几年检索模型发展如何,深度学习模型是否在其中发挥作用,比如文本匹配模型。
用户意图识别。用户意图识别通过用户query、结合搜索日志等计算用户的意图,意图与文档主题相符的应该排序更靠前。用户意图识别可以在网络上找到一些博客分享,但是没有看到特别多的论文资料。也许这个是一个更偏工程的问题。