该部分总结自《Spark权威指南》第五章内容,个人学习笔记和记录。
引言
本章是《Spark权威指南》的第五章内容,介绍DataFrame的基本操作。本章从DataFrame的模式(Schema)、列、记录和行、DataFrame的转换一次进行介绍。整个逻辑也很清楚,先介绍了组成DataFrame的基本元素模式、列和行,然后再介绍DataFrame可以执行的一些转换操作。
Schema
在这里再一次提到了模式(Schema)的概念,它定义了DataFrame的列名和数据类型。模式可以从数据源定义也可以显示定义。从数据源定义意味着spark在读取数据时通过数据源自动去推断这个列可能的数据类型,由于json或者csv这种文本文件是不带数据类型信息的,因此从数据源定义可能会导致精度问题,例如将long类型设置为整型。
显示定义则是由开发人员在代码中定义每一列的信息,包括列名、数据类型等内容。书中给出了如下的代码:
1 | mySchema = StructType[ |
上面的代码是显示定义模式并读取数据的示例,可以看到在定义数据类型时没有使用python的数据类型str,int等,而是使用StringType,LongType等Spark自己定义和维护的类型。
列和表达式
Spark中的列和电子表格、pandas DataFrame中的列类似,可以对其进行选择、操作和删除。可以使用col或者column方法来引用列。
1 | from spark.sql.functions import col, column |
通过DataFrame.columns可以访问一个DataFrame的所有列名。
记录和行
之前有介绍过,DataFrame中的每行是一条记录,而记录表示为Row类型的对象。因此DataFrame可以看作是Row对象的集合。
在python中,可以直接实例化Row对象来创建行,如下:
1 | from pyspark.sql import Row |
并通过下标来直接访问行中的元素
1 | myRow[0] |
DataFrame具有模式,但是Row没有模式。关于这一点,目前还不是很理解。
DataFrame转换
前面介绍了模式,列和行,那么DataFrame的基本组成部分就已经介绍完。在我们得到DataFrame后,下面要做的就是如何对DataFrame进行操作和在DataFrame上面进行计算了。
创建DataFrame
1. 通过读取json,csv数据来创建DataFrame
2. 通过创建Row对象和模式对象,并将两者作为参数传入spark.createDataFrame来创建DataFrameselect和selectExpr
可以在DataFrame上通过select和selectExpr来使用SQL查询。
添加列
可以使用withColumn在DataFrame中添加一列。
1 | df.withColumn('NumberOne', lit((1)) |
withColumn方法第一个参数是列名,第二个参数是列值,因此上面的方法在DataFrame中添加了NumberOne列,该列中存储的值都是1。
如何添加非常量列呢?
重命名列
可以使用DataFrame的withColumnRenamed方法来对列进行重命名,该方法第一个参数是原始列名,第二个参数是新的列名字符串。
保留字符和关键字
当列名中包含空格或者连接符时,可以使用反引号将列名括起来,不然会报错。但是如果使用col对列名进行引用则不需要反引号将列名括起来。
区分大小写
spark默认情况下不区分大小写。
这里是什么东西不区分大小写,书中没说?列名还是什么?
删除列
使用drop方法删除列。
1 | df.drop(列名1,列名2) |
更改列的类型
1 | df.withColumn(列名1,col(列名2).cast('long')) |
通过上面的命令,列名1将具有long类型和列名2对应的数据
过滤行
可以使用filter或者where方法,filter和where接受一个表达式。
获取非重复行
首先通过select选择相关的列,然后再通过distinct去重,得到不包含重复的行。
1 | df.select(列名1,列名2).distinct() |
随机采样
sample方法提供了采样功能,可以通过参数确定采样比例和随机种子。
随机分割
随机分割将DataFrame切分为几个子集,例如机器学习中的训练集、验证集和测试集。可以使用randomSplit方法进行随机分割,具体参数参看API文档。
串联和附加行
通过union方法可以将两张具有相同模式的列合并起来。列数不变,行数增加。
排序行
sort或者orderBy可以根据某列来对DataFrame的行进行排序。desc和asc用来描述升降序,是spark定义的方法。
限制
limit方法。和SQL中类似,使用limit可以从DataFrame中提取有限数量的数据行。
分区与合并
repartition方法可以用于对DataFrame进行分区,参数可以是分区的数量以及列。参数为列时说明希望DataFrame根据列进行分区。
分区具体是怎么进行的,产生什么物理效果?
将行收集到驱动程序中
DataFrame在驱动程序中收集数据的方法很多,包括show、take、collect和toLocalIterator。具体参看API文档。show和take可以传入整数参数,从而空值收集数据的数量。collect会从所有分区将数据收集到驱动程序,当数据规模很大时该操作有风险。toLocalIterator则是在驱动程序中形成迭代器,可以逐个分区扫描数据。
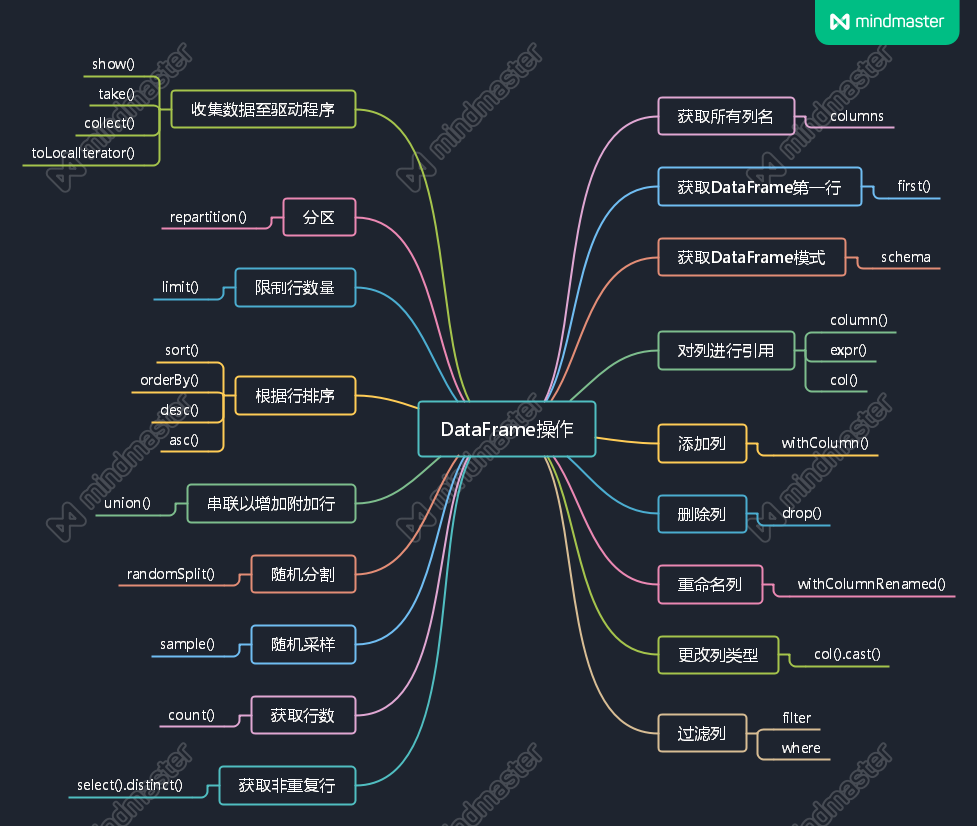
思维导图
本章基本在围绕DataFrame介绍相关的API,通过思维导图捋一下思路。
最后
DataFrame、Schema等内容在之前的章节有提及,但是都没有交详细的介绍,示例代码以及说明也很少。在之前章节看过之后基本只是了解到有这样一个东西。但是在这个一章中,对DataFrame则做了更详细的介绍,包括通过示例代码说明了一些相关的API以及解释相关的概念。
笔记三种的数据类型和模式在这里也有了更清楚的认识和理解。