最近由于各种原因,工作重心迁移到了CTR预估上来了。由于之前并没有对CTR预估有很多的了解和实践,那么借助这次机会,好好学习一下CTR预估相关的内容。主要的学习目标包括了解整个CTR预估的发展变迁;其次了解一些经典的、前沿的CTR预估模型,应用到当前项目当中;最后是通过同行的开源博客了解行业在CTR预估这件事情上的做法。
论文
http://xxx.itp.ac.cn/pdf/1606.07792.pdf
前言
WDL(Wide & Deep Learning for Recommender Systems)是谷歌在2016年提出的一个经典的推荐模型。虽然该模型已经提出了很长时间,但是一直到现在也依旧是一个较强的baseline,甚至在一些推荐项目初期,也会优先选择这样一个模型作为基线快速上线和迭代。
WDL,也叫Wide & Deep,从名字也可以看出来主要由两个部分构成,即Wide侧和Deep侧。两个模块的设计分别为了解决不同的问题。Wide侧更注重记忆,而Deep侧更注重泛化。(这里怎么理解其中的记忆和泛化)。
模型结构
Wide&Deep的整体模型结构如下图所示:
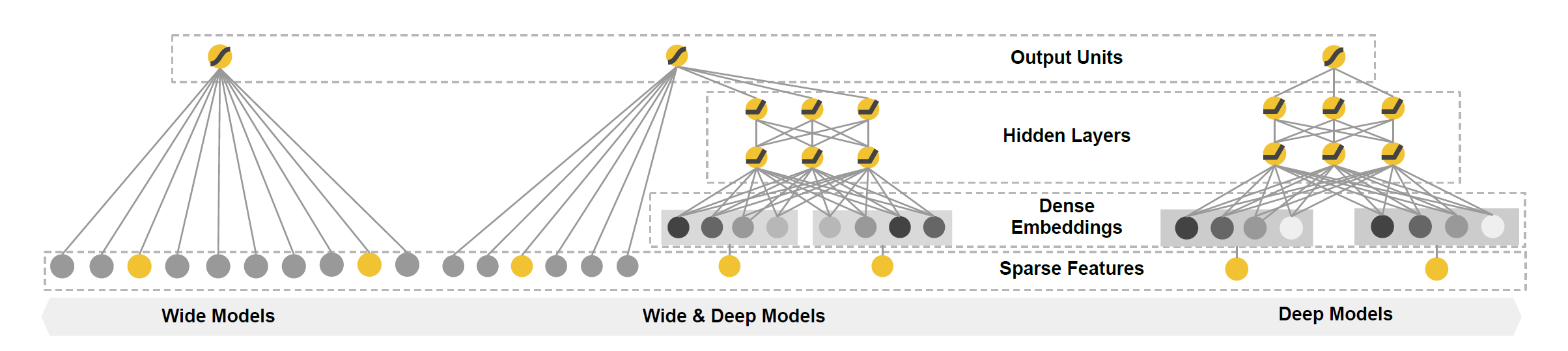
可以看到,左侧是一个简单的线性回归,右侧则是NN模型,一个简单的前馈神经网络,而两者进行结合就是中间的Wide&Deep模型。
Wide组件
Wide其实就是一个线性回归:
$$
y = W^T X + b
$$
其中$y$表示线性回归的输出,$W=[w_1,w_2,…,w_d]$表示参数,$X=[x_1, x_2, …, x_d]$表示特征向量,$b$是一个偏置项。
特征向量中的特征除了原始的特征外,还有经过转换的特征。比如一种最重要的转换特征是交叉特征,即通过两个特征进行交叉得到一个新的特征。交叉特征的引入在线性模型中增加了非线性因素,增加了特征的表达能力。但是这种交叉需要人工进行设计,需要耗费大量时间进行特征工程,为此后续产生了很多自动进行特征交叉的模型。
Deep组件
Deep侧是一个简单的前馈神经网络,可以用如下公式表示:
$$
a^{(l+1)} = f(W^{(l)}a^{(l)} + b^{(l)})
$$
在Deep侧的特征处理中,对于一些稀疏的、高维的特征比如:性别、地域、学历等,可以使用类似自然语言处理的方式,将他们embed成一个低维向量,然后送到模型中进行训练。这个向量可以想办法预训练、也可以随机初始化。
联合训练
网络有两个独立的部分,那么怎么将两者联合起来训练呢?wide&deep将两个模型的输出加权相加后,通过一个公共的logistic loss进行训练。可用如下的公式进行表示:
$$
P(Y=1|X) = \sigma{( W^T_{wide}[X, \phi(X)] + W_{deep}^T a^{l_f} + b)}
$$
其中Y表示二分类类目标签,在搜索或推荐中可以表示点或者不点,在应用商店中可以表示安装或者没安装等。$\sigma(\cdot)$表示sigmoid函数,$\phi(X)$表示基于原始特征产生的交叉特征,$W_{wide}$表示线性模型参数,$W_{deep}$表示deep最后一个激活项的参数。
特征处理
自然语言处理的任务大多都是切词,通过embedding lookup将词embed成向量,然后模型针对向量进行一系列的操作,最后得到最终的输出。而对于排序模型而言,通常有整型特征和浮点型的特征,如何将这些特征进行处理并输出模型中也是我较为关心的一个问题。
思考总结
论文中多次强调了记忆和泛化对于推荐系统的重要性,而wide&deep也是对应的解决这两个问题。wide侧的线性回归解决记忆问题,可以有效的记住稀疏的交叉特征。deep侧则是通过低维向量泛化之间没有见过的一些交互特征。