该部分总结自《Spark权威指南》第三章内容,个人学习笔记。
Spark工具集
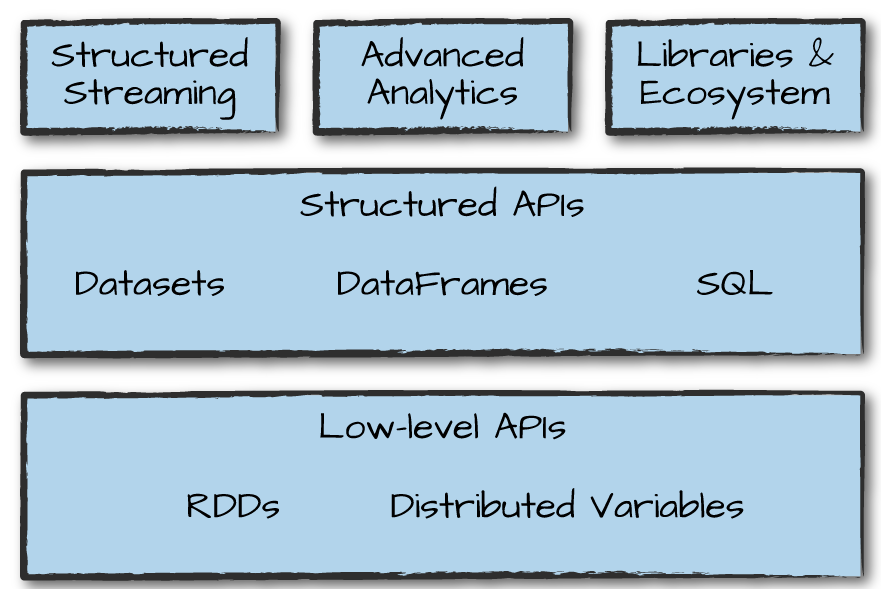
下图是Spark工具集的概览,包括了结构化的API、低级的API,结构化流、机器学习相关的MLlib进行高级数据分析、第三方库/包等。
提交上线应用环境
我们可以在spark提供的交互性shell环境中进行交互式编程,但是这种仅适合于进行在线数据分析。当需要开发大型项目,显然这种交互式的编程方式不太方便。这时候需要我们打包自己的spark程序,然后使用spark提供的spark-submit工具提交到集群上运行。spark-submit在spark安装目录的bin目录下,其实本身是一个shell脚本,其内容如下:
1 | if [ -z "${SPARK_HOME}" ]; then |
在上面的脚本代码中可以看到SPARK_HOME这个环境变量,这个脚本需要依赖这个环境变量定位spark的安装位置。平时我们在安装各个框架、库的时候,都或多或少会碰到需要在系统环境变量中配置某些指定的变量,其中道理就在这里。环境变量的配置一方面是定位框架安装的路径,另一方面是框架中自行开发的一些工具脚本需要依赖这些环境变量来执行,本质依旧是告诉操作系统我将框架安装在了什么地方,让系统可以找得到相关的依赖或者命令。
关于如何利用spark-submit如何提交程序,有哪些相关参数,每个参数具体什么含义在需要的时候再查询。
类型安全的API——DataSets
DataSets是Spark提供的结构化且类型安全的API,但是其仅能在Java和Scala中使用。什么是类型安全?目前对类型安全的API带来的优势还没有什么实际感受。
结构化流处理(Structured Streaming)
Spark提供了以批处理的方式处理结构化的数据,比如DataFrame结构和Spark SQL。而所谓的结构化流,其实就是使用流处理的方式来处理结构化数据。一个简单的例子是销售记录。一份消费记录记录的用户id,消费时间,消费金额等信息。批处理在每天结束时,一次性计算每天的消费统计信息。而流处理通过实践窗口,实时计算一些统计信息,比如一个小时内每个客户的消费金额等。批处理是静态的,需要等到每天结束时,数据都不变的情况下进行整体计算。流处理是动态的,数据在不停变化,因此流处理的计算结果也在根据数据的变化而变化。
机器学习和高级分析
Spark提供了MLlib库以支持机器学习应用的开发,MLlib库允许进行预处理、修改、模型训练和数据的大规模预测。因此,一些分类和回归算法现在可以借助该库在集群上进行实现。为什么不在单机上进行呢?这个在之前的介绍也已经提到过,spark是为了解决单机资源不足以支撑大数据计算而产生的计算引擎。我们平时习惯了在小规模数据上编写代码,一次性将所有数据读入内存并进行模型的训练,但是在实际生产应用中数据规模十分庞大,单机是不足以处理如此大规模数据的。MLlib则是在集群进行计算,解决单机资源不足的问题。
低层次APIs
RDD(分布式数据集)是Spark中的一种低层次的API,它向用户揭示了spark的物理执行特性(比如分区)。一般建议使用DataFrame等高级的API,而在处理一些原始或者非结构化的数据时使用RDD。
Spark R
Spark提供对R语言的支持,目前不关心。
Spark生态系统和软件包
Spark包可以在spark-packages.org中查看相关索引。第三方开发的包可以帮助我们快速开发,避免重复造轮子。在使用python的过程中,这一点是深有体会的。